The Global Market Index (GMI) that’s frequently cited on these digital pages is a robust benchmark for the simple reason that it holds all the major asset classes in market-value weights and shuns rebalancing. In other words, GMI is a measure of global beta that’s available to anyone and everyone, at low cost and in a forecast-free framework. In short, a monkey could replicate GMI. As it turns out, a monkey can do quite well through time with this strategy. Nonetheless, readers periodically ask why GMI’s relatively short historical track record is a reliable guide to the future? Great question, and one that deserves more than a trivial answer.
For starters, there’s a fair amount of theory that tells us to expect that a market-value weighted mix that’s representative of the assets in question will deliver competitive returns through time (for details, see my book Dynamic Asset Allocation). In fact, the historical record more or less jibes with theory on this point, which explains why indexing has become so popular over the years.
What’s true for individual asset classes (stocks, bonds, etc.) tends to be true for asset allocation. Indeed, GMI’s performance over the past decade, relative to more than 1,100 multi-asset class mutual funds with track records of at least 10 years, fares quite well against this broad sampling of professional money managers/asset allocators. Nonetheless, GMI’s inception date is the close of 1997. That’s an arbitrary date, but my reasoning is that the further back in time you go, the thinner the choices for asset classes, which is problematic if we’re building a multi-asset class benchmark. How did junk bonds perform in the 1973-75 recession, for instance? Unclear, since reliable data bases on this market for that time period are virtually non-existent.
As a practical compromise, GMI’s history is relatively short. I say “short” in the context of recognizing the we have historical data on US stocks and bonds that starts in the early 1800s. The challenge, then, is deciding if GMI’s record is a reliable sample for modeling ex ante risk and return. In fact, that’s a relevant issue for any data set of investment returns, even for two centuries of performance records for US equities and fixed income. Sure, 200 years looks reliable on first glance, but it’s still not clear that any one 200-year history is the definitive and representative sample for developing perspective on the future. A single historical example could be an anomaly because the particular economic and financial circumstances that generated the results aren’t likely to repeat. The future, in other words, may look very different from the past.
Okay, so how can we manage this risk by reducing the surprise factor? There are a number of statistical inquiries we can deploy to investigate the very real possibility that the historical sample we’re looking at isn’t representative of what we’ll face going forward. Among the various applications that I use for modeling/analyzing return series, two are relevant here:
1. simulated data, based on plugging in various risk assumptions
2. bootstrapping the data, which means taking the historical record available and reshuffling the order and frequency of values x times to explore the potential for alternative outcomes relative to the one track record that actually unfolded.
Let’s focus on the second technique and see what it tells us about GMI’s track record. To keep this review brief, we’ll only look at monthly returns. In a real-world example, however, we’d also explore returns across longer spans: 1-, 3-, and 5-year periods, for instance. Meanwhile, a very brief (and very simple) review of bootstrapping. Let’s say you have an ordered sequence of numbers: 1 through 10, i.e., 1,2,3,4,5, etc. The question is how might these 10 numbers might appear in other sequences, such as: 8,7,5,1,2,4,3,10,6,9. Keep in mind that another sequence might reflect a greater frequency (or absence) of certain values, such as: 8,4,5,2,9,1,1,1,1,1. If the sequence, and related distribution, is relevant (as it is with investing), exploring the possibilities is worthwhile. Let’s apply the same question to GMI’s historical record of 187 monthly returns. To be precise, let’s examine different alternative return histories by reshuffling, in a random way, the 187 monthly returns of actual data. In fact, let’s reshuffle this data deck 100,000 times and compare the aggregated results with the actual historical record. In effect, we now have 100,000 historical return series to analyze vs. just one.
To begin, let’s first look at the actual distribution of the 187 monthly returns as stated in history. (All the analytics and charts, by the way, are run in R software):
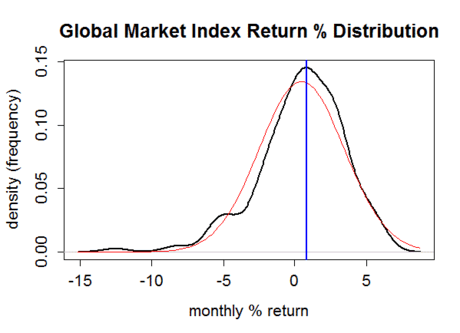
The black line in the chart above shows the distribution of monthly returns. The x axis on the bottom tracks the range of returns, which have been as high as 6.17% and as low as -12.53%. The vertical blue line is the median return for the 187 monthly performance numbers: 0.84%. The red curve depicts a perfectly random distribution. If GMI’s returns matched a perfect random walk, the results would follow the red line. As you can, GMI returns, like most performance histories in financial markets, aren’t perfectly random. Instead, there are fat tails—extreme returns, positive and negative, that show up with greater frequency (indicated on the y axis on the left) than a random distribution predicts.
The basic message is that GMI’s returns exhibit a slightly positive skew and are prone to bigger losses than expected in a normal distribution. This profile isn’t terribly surprising, given what’s unfolded in markets over the past 187 months.
Now let’s reshuffle (resample) the existing return history for GMI and compare the results. Here’s how 100,000 resampled histories stack up:

The main takeaway in the second chart is that the instances of extreme returns—both positive and negative—are more frequent relative to the actual sample from history. That’s a sign that we should expect more extreme returns than the limited historical record suggests–especially in the realm of losses. That doesn’t mean that GMI’s relative returns will be any less competitive against a broad universe of active managers. Indeed, those active managers are prone to the same risks that hassle GMI.
In any case, we can and should run several stress tests on GMI, or any other investment strategy, for that matter. Developing a deeper understanding of what may be in store for your portfolio, regardless of design, is essential from a risk management perspective. Bootstrapping is one technique to bring a bit more clarity about what may be lurking around the corner. In another post I’ll run the numbers on GMI with a Monte Carlo simulation for another perspective.
Meantime, the analysis above reinforces an ageless lesson in the money game: the past isn’t necessarily representative of future results.