Is the U.S. economy headed for a new recession? The risk is clearly elevated these days, in part because the euro crisis rolls on. The sluggish growth rate in the U.S. isn’t helping either. But with ongoing job growth, albeit at a slow rate, it’s not yet clear that we’ve reached a tipping point. Given all the mixed signals, however, forecasting is unusually tough at the moment. It’s never easy, of course, but it’s always necessary just the same. But how to proceed? The possibilities are endless, but one useful way to begin is with so-called autoregressive integrated moving averages (ARIMA). It sounds rather intimidating, but the basic calculation is straightforward and it’s easily performed in a spreadsheet, which helps explain why ARIMA models are so popular in econometrics. A more compelling reason for this technique’s widespread use: a number of studies report that ARIMA models have a history of making relatively accurate forecasts compared with the more sophisticated competition.
As a simple example of the power of ARIMA forecasting, let’s consider what this statistical tool is telling us about the next quarterly change in nominal GDP for the U.S. Making a few reasonable assumptions (discussed below), a basic ARIMA forecasting model predicts that fourth quarter 2011 nominal GDP will rise 4.7% at a seasonally adjusted annual rate. For comparison, that’s slightly lower than the government’s initial estimate of 5.0% growth for the third quarter. (Remember, we’re talking here of nominal GDP growth vs. real growth, which strips out inflation. Real GDP is the more popularly quoted series.)
For perspective, let’s compare the history of my ARIMA forecast with GDP predictions via the Survey of Professional Forecasters (SPF). SPF data is available on the Philadelphia Fed’s web site and in this case I focus on nominal GDP. To cut to the chase, ARIMA has a history of dispatching superior forecasts compared with SPF. To be precise, I’m comparing ARIMA forecasts with the mean quarter-ahead prediction of economists surveyed quarterly in the SPF reports.
Ok, let’s take a closer look at some of the finer points by reviewing a few basic ARIMA concepts. Keep in mind that in the interest of brevity I’m glossing over the details. For a complete discussion of ARIMA, an introductory econometrics text will suffice. One of many examples: Peter Kennedy’s A Guide to Econometrics. Meanwhile, the main point with ARIMA forecasting is that it’s a tool for using a time series’ history to make a forecast. Yes, it’s naïve, but the fact that ARIMA’s errors tend to be low relative to many if not most other forecasting techniques makes this approach worthwhile. It’s not a crystal ball, of course, and so ARIMA forecasts should be considered in context with other predictions using alternative models.
As for ARIMA, the first step is taking the data series (in this case the historical quarterly nominal GDP numbers) and regressing them against a lagged set of the same data. For the analysis here, I’m regressing each quarterly GDP number against 1) the previous quarter; 2) two quarters previous; and 3) four quarters previous. Next, I ran a multi-regression analysis on this set of lagged data to estimate the parameters, which tell us how to weight each lagged variable in the formula that spits out the forecast. To check the accuracy of the parameter estimates, I also ran a maximum likelihood procedure. (As a quick aside, all of this analysis can be easily done in Excel, although more sophisticated software packages are available, such as Matlab and EViews.)
ARIMA’s forecasts are naïve, of course, but based on history it does fairly well compared with SPF. The in-sample forecasting errors (residuals, as statisticians call them) for ARIMA’s average deviation from the actual reported GDP number is a slight 0.0049% since 1970. That’s a mere fraction of SPF’s 3.06% residual over the past 30 years. There are several additional error tests we can run, but the simple evaluations above offer a general sense of how a naïve ARIMA model can provide competitive forecasts vs. the expectations of professional economists.
Alas, like all econometric techniques that look backward as a means of looking ahead there’s the risk that sharp and sudden turning points in the trend will surprise an ARIMA model. That’s clear by looking at recent history, as shown in the chart below. Note that when the actual level of nominal GDP turned down in 2008 as the Great Recession unfolded, ARIMA’s forecasting error rate increased. But ARIMA fared no worse than the mean SPF predictions. In fact, you can argue that ARIMA did slightly better than SPF, as implied by tallying up the errors for each during 2008 and comparing one to another.
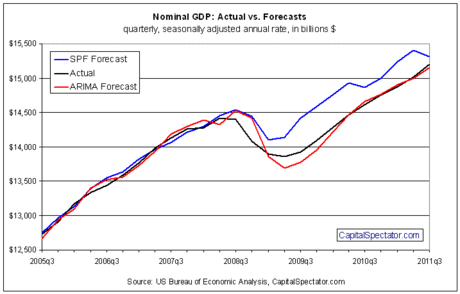
Errors are inevitable in forecasting. The goal is to keep them to a minimum, a task that ARIMA does quite well. But that assumes a certain amount of trial-and-error testing for building and adjusting ARIMA models. Still, the future’s always uncertain. But the errors can help improve ARIMA forecasts. By modeling the errors and incorporating their history into ARIMA’s regressions, there’s a possibility that we can reduce the error in out-of-sample forecasts going forward. That’s because if you design an ARIMA model correctly, the errors should be randomly distributed around a mean of zero. In other words, errors through time should cancel each other out. In that case, past error terms can be useful for enhancing ARIMA’s forecasting powers, i.e., reduce the magnitude of the errors in the future.
Yes, we still need an understanding of economic theory to adjust, interpret and design ARIMA models for predicting GDP and other economic and financial data series. But considering the simplicity and relative reliability of this econometric technique, ARIMA forecasting is a no-brainer. At the very least, it provides a good benchmark for evaluating other forecasts.
I wouldn’t say “so-called” technique for something every econ grad student learns that’s entirely not controversial.
Technically what you did was without the MA components (unless you did something different with the MA part). Anyway, you don’t really address the whole unit root vs. stationarity problem. The ideal way to perform this estimation is to take the log changes of X and regress that on its lags. Then you project to horizon in terms of changes. This is because X is I(1) and you need to convert to I(0) by taking the changes, this is the whole integrated part. You can have problems with longer-term forecasts if you do not do this.
I also do not know how you get your forecast error. I took the SPF and did LN(NGDP2/NGDP1) to get the one quarter ahead forecast and compared that to NGDP (post-revisions of course) and got a standard deviation of 0.6% for SPF and 0.8% for an AR(4) (also tried AR(2), roughly the same) model on log changes in NGDP. This is from Q4 1968 to present. Of course the SPF may incorporate some data that was not known at the beginning of a quarter or something, but I wouldn’t try to oversell ARIMA.
John,
Yes, there’s much, much more to say about ARIMA and this post barely scratches the surface. That said, I did take the second differences in the GDP changes to detrend the data and satisfy the weakly stationary requirement. Alas, I failed to mention that in the post, although the calculation I report incorporates this adjustment. As for the differences in our error analysis, that may be due to focusing on different SPF predictions of GDP. There are several survey forecasts in each quarter and I’m looking only at the mean next quarter prediction. In addition, I also ran the numbers using alternatives for forecast evaluation, including avg absolute error and root avg squared error and ARIMA still comes out on top. There may be differences in our methodologies for parameter estimation that accounts for the divergent results. That’s another reminder that model design assumptions are critical if you want to be confident with the output. As for your warning about overselling ARIMA, I agree, as I noted in the post. It’s a useful technique for comparing and contrasting other predictions. But using ARIMA (or any other forecasting methodology) in a vacuum is asking for trouble. And, of course, we need to have a good understanding of economic theory to interpret ARIMA’s guesstimates. In short, all the usual caveats apply.