US economic growth in the second quarter is widely expected to rebound after Q1’s stall-speed rise of just 0.5% (seasonally adjusted annual rate). The question is how much a rebound will we see when the Bureau of Economic Analysis (BEA) publishes this year’s “advance” Q2 GDP report on July 29?
It’s still early in the quarter and so there’s a wide range of guesstimates. The good news is that most forecasts currently project a round of improvement. It’s anyone’s guess if those estimates will hold up as the remaining hard data for Q2 rolls in over the next two months. Meantime, let’s get up to speed on the crowd’s outlook at the moment.
The Wall Street Journal’s mid-May survey of economists anticipates Q2 GDP growth will revive to 2.2% (based on the average estimate). The Atlanta Fed’s May 17 nowcast is even higher at 2.5%. Goldman Sachs yesterday went further, raising its Q2 growth estimate to 3.0% after the government reported a smaller-than-expected widening of the trade deficit in April. By contrast, the dismal scientists at BMO Capital are looking for a relatively weak rebound of just 1.4%, as of May 20. The New York Fed’s May 20 nowcast isn’t much stronger at 1.7%. Note, however, that PMI survey data for May translates into hardly any revival at all for Q2 growth. Markit Economics is projecting a fractional increase in growth to just 0.7%, the firm advised yesterday.
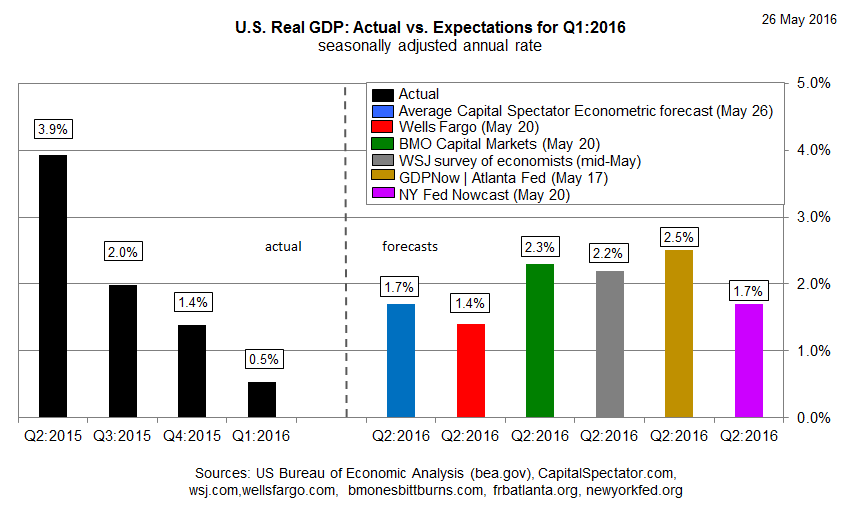
Meantime, the Capital Spectator’s average projection for several econometric estimates is also 1.7% at the moment.

As updated estimates are published, based on incoming economic data, the chart below tracks the changes in the evolution of The Capital Spectator’s projections.

Finally, here’s a brief profile for each of The Capital Spectator’s GDP forecast methodologies:
R-4: This estimate is based on a multiple regression in R of historical GDP data vs. quarterly changes for four key economic indicators: real personal consumption expenditures (or real retail sales for the current month until the PCE report is published), real personal income less government transfers, industrial production, and private non-farm payrolls. The model estimates the statistical relationships from the early 1970s to the present. The estimates are revised as new data is published.
R-10: This model also uses a multiple regression framework based on numbers dating to the early 1970s and updates the estimates as new data arrives. The methodology is identical to the 4-factor model above, except that R-10 uses additional factors—10 in all—to forecast GDP. In addition to the data quartet in the 4-factor model, the 10-factor forecast also incorporates the following six series: ISM Manufacturing PMI Composite Index, housing starts, initial jobless claims, the stock market (Wilshire 5000), crude oil prices (spot price for West Texas Intermediate), and the Treasury yield curve spread (10-year Note less 3-month T-bill).
ARIMA GDP: The econometric engine for this forecast is known as an autoregressive integrated moving average. This ARIMA model uses GDP’s history, dating from the early 1970s to the present, for anticipating the target quarter’s change. As the historical GDP data is revised, so too is the forecast, which is calculated in R via the “forecast” package, which optimizes the parameters based on the data set’s historical record.
ARIMA R-4: This model combines ARIMA estimates with regression analysis to project GDP data. The ARIMA R-4 model analyzes four historical data sets: real personal consumption expenditures, real personal income less government transfers, industrial production, and private non-farm payrolls. This model uses the historical relationships between those indicators and GDP for projections by filling in the missing data points in the current quarter with ARIMA estimates. As the indicators are updated, actual data replaces the ARIMA estimates and the forecast is recalculated.
VAR 4: This vector autoregression model uses four data series in search of interdependent relationships for estimating GDP. The historical data sets in the R-4 and ARIMA R-4 models noted above are also used in VAR-4, albeit with a different econometric engine. As new data is published, so too is the VAR-4 forecast. The data sets range from the early 1970s to the present, using the “vars” package in R to crunch the numbers.
ARIMA R-NIPA: The model uses an autoregressive integrated moving average to estimate future values of GDP based on the datasets of four primary categories of the national income and product accounts (NIPA): personal consumption expenditures, gross private domestic investment, net exports of goods and services, and government consumption expenditures and gross investment. The model uses historical data from the early 1970s to the present for anticipating the target quarter’s change. As the historical numbers are revised, so too is the estimate, which is calculated in R via the “forecast” package, which optimizes the parameters based on the data set’s historical record.
Pingback: US Economic Growth Expected to Rebound in Second Quarter - TradingGods.net