Last month I tested random rebalancing strategies based on dates and found that searching for optimal points through time to reset asset allocation may not be terribly productive after all. Let’s continue to probe this line of analysis by reviewing the results of randomly changing asset weights for testing rebalancing strategies.
I’ll use the same 11-fund portfolio that’s globally diversified across key asset classes with a starting date of Dec. 31, 2003. The benchmark strategy is simply rebalancing the portfolio at the end of each year back to the initial weights, as defined in the table below.
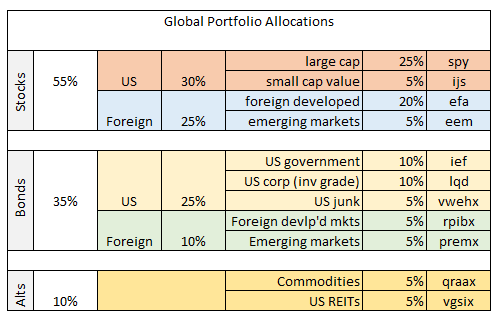
Let’s assume that the benchmark strategy is someone’s best effort at portfolio design. Our fictional investor—let’s call him Ronald–has thought long and hard about asset allocation and decided that the portfolio mix above is the way to go. Ronald has back-tested the strategy with actual data with the funds listed above and thinks that the results are encouraging. A $100 investment at the start date (Dec. 31, 2003) increased to just over $200 as of Oct. 2, 2015. Ronald concludes that the portfolio’s 100% cumulative gain over the sample period is pretty good. He pats himself on the back and goes out for a celebratory dinner, confident that he’s built a winning portfolio. In other words, Ronald’s convinced that he possesses a fair amount of skill in the art/science of building and managing portfolios through time.
While Ronald’s away at the Overconfidence Café, let’s analyze his portfolio design by comparing it with random portfolios. We’ll use the same funds in the table above but randomly vary the weights for each of the portfolio’s assets. To ensure a fair test, we’ll keep the random weights within the same range in the table above—a minimum of 5% up to a maximum of 25%. Using R (you can find the code here), we’ll create 1,000 portfolios, each with a randomly selected mix of different weights for the 11 funds. To match Ronald’s portfolio, the strategies are 1) rebalanced back to the randomly selected target weights at the end of each year; 2) are always invested in each fund in some degree; 3) but no shorting or leverage is allowed. In sum, the random portfolios are identical to Ronald’s strategy with one exception: the asset weights are allowed to wander within a 5%-to-25% range.
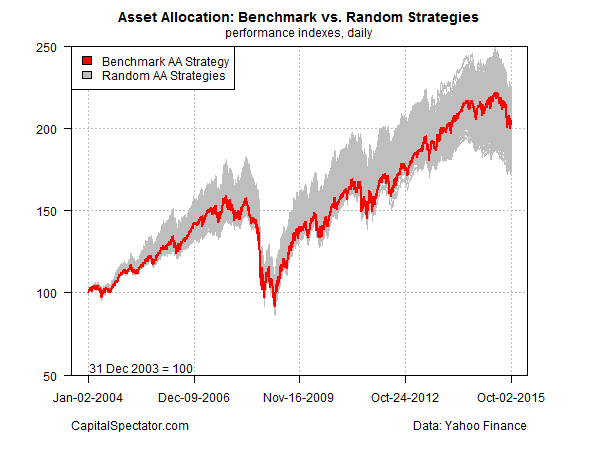
The chart below compares Ronald’s strategy (red line) with the 1,000 portfolios that randomly vary the asset weights (gray area). As you can see, Ronald’s portfolio results are more or less average relative to the randomly generated results. The implication: Ronald’s skill may be a figment of his imagination, courtesy of looking at one return sample, namely, the portfolio he designed and back-tested.
For another perspective, let’s compare the ending value–204–of Ronald’s benchmark portfolio for the sample period with the distribution of ending values for the 1,000 randomly generated strategies (black line). I’ve also added the median outcome for the random portfolios (blue line).
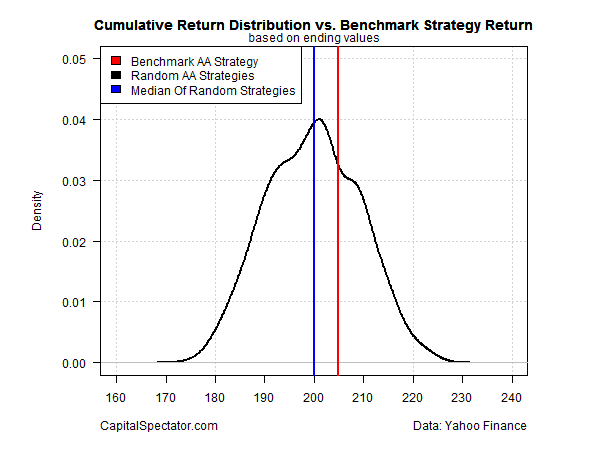
The good news for Ronald’s ego is that his portfolio earned a slightly above-median return. Is that evidence of skill? Maybe, but we’d have to run additional tests for a deeper level of confidence before crowning Ronald as an asset allocation wizard.
For instance, we could review the drawdown history of Ronald’s portfolio and compare it with the randomly generated strategies. Analyzing the portfolio’s Sharpe ratio, Sortino ratio and other risk metrics in context with the random results is a productive line of inquiry as well. The question is whether Ronald’s portfolio takes on substantially more risk than is necessary to earn what appears to be a middling performance?
The larger point is that by creating 1,000 random portfolios we have a robust data set for analyzing risk and skill. The toy example above can easily be expanded to generate a more nuanced set of random portfolios, offering a more realistic array of investment possibilities. What if we expanded the range of weights to, say, zero up to 50% for any one fund? How would the results change if we added a momentum filter for choosing weights for each fund? We could also impose a volatility limit. The possibilities are endless. Ideally, the testing would be customized to match the investor’s risk tolerance, goals, and other factors that are unique to a given strategy under the microscope.
The key lesson is that using a set of random portfolios to evaluate a given strategy is a powerful tool. By comparison, the standard approach—comparing a portfolio to one idealized benchmark or a peer group in the same strategy neighborhood—is inferior as a methodology for analysis. Why? Because cherry picking a handful of funds for a benchmark isn’t representative of what could happen. If we’re testing a portfolio strategy, it’s essential to review all the possible outcomes, even if those outcomes never occurred in the real world.
Granted, random portfolios aren’t a crystal ball—the future’s still uncertain. But if you’re analyzing investment strategies without the benefit of random portfolios, you’re overlooking a lot of valuable insight–insight that may spare you grief later on. Maybe someone should tell Ronald.
Pingback: Quantocracy's Daily Wrap for 10/06/2015 | Quantocracy
Hi,
Great post on a subject which is close to my heart.
If you haven’t already, I would take a look at the work done by Patrick Burns, http://www.portfolioprobe.com/blog/
He has quite a few posts on ‘random portfolios’ as well as a few more technical papers on the subject. His R package also goes very deep into this particular rabbit hole.
Regards,
Emlyn
Pingback: 10/12/15 – Monday’s Interest-ing Reads | Compound Interest-ing!
I’ve read other analysis of rebalancing that suggests anything from 6 mos to 1.5 years is pretty equivalent, and one year seems as good a frequency as any, and rebalancing when you are x% out of balance with your base portfolio seems to yield about the same return. Interesting to see similar conclusions.
As for portfolios, where do you get the ‘range’ of possible random portfolios from? Just curious if there are accessible sites with the information. I also get curious if a 30 year bull market in bonds modifies the results you get. For instance I have a model portfolio that should return about 2% more than a US 60/40 portfolio, with a 1% increase in std deviation…. based on roughly the past 30 years of actual data. Would those gaps look very different if I went back 30 more years? Would bond behavior be different enough that the sharpe/sortino ratios, relative return and drawdown all change significantly? I am not sure I know enough to understand how much risk I would truly take on by adopting this portfolio. I imagine this is a common feeling!
Pingback: IMHO BEST LINKS FROM QUANTOCRACY FOR THE WEEK 5 OCT 15 — 11 OCT 15 | Quantitative Investor Blog
AmericanFool,
Great questions. Too many in fact to address in a reply comment other than to say that exploring the points you raised (and more) are essential for real-world investment analytics. As for my toy example in the post, the range of weights I use to vary the random portfolios is simply using the numbers for the test portfolio, as defined in the table. These are just rough choices for creating a simple multi-asset mix, arguably using reasonable if less-than-optimal weights. I’ve used this test portfolio in the past and partly for continuity I do so here. In short, the range of numbers are merely a rough approximation of what might be considered a diversified mix. It’s a decent set of weights for testing how random portfolios stack up.
–JP
Hi. Great post.
I was checking the linked R code. If I understand correctly, random weights are generated by ” w.global <-prop.table(runif(11,min,max)) "
with min=0.05, max=0.25;
Unless I am mistaken, this will not really give uniform weights in the min-max range, due to the scaling by row (to add up to 1).
Am I missing something?
thanks
Mark
Mark,
the
prop.table(runif(11,min,max)command generates 11 random weights that a) add up to 1.0 and b) are within the min/max range, which in this case is between 5% and 25%. As an example of one run, execute this in R:test <-prop.table(runif(11,0.05,0.25))The result is that the "test" file holds a random set of 11 weights between 0.05 and 0.25 that sum to 1.0, which you can check with:
sum(test)range(test)
Hope that helps.
--JP